Framework Documentation
Platform Architecture
TL;DR:
- Platform engineering requires rethinking environments
- Architecture decisions must take multiple factors into consideration
- Platforms can scale to meet demand or new requirements
Rethinking Environments
Kubestack believes that platform teams are product teams. You build a product and provide it as a service. Just like a cloud provider. To succeed in building and sustainably maintaining a platform long-term, you must rethink environments.
Internal vs. external environments
A common practice of product teams is to have internal and external environments. Development or staging are internal environments, used to ensure high product and service quality. And production is the external, user-facing environment.
Cloud providers work like that too. All customer environments, dev, stage and prod always run on the cloud provider's external environment.
If you have a background in operations, you may find this fundamentally different to the very common one-to-one relationship between infrastructure and application environments you may be used to.
Kubestack is designed to help platform teams build like product teams and operate like cloud providers. When you adopt Kubestack, you review and validate any change against an internal environment before promoting it to an external, user-facing environment.
Two or more environments
A platform should have at least two environments, one internal to the platform team and one external, or user-facing one. All environments will be complete replicas of your platform, configured from a single code base that defines all platform components. Kubestack provides inheritance based configuration to sustainably handle required differences between environments.
By default, Kubestack scaffolds platforms with two environments:
- internal (default ops): is used to preview and validate changes before they are promoted
- external (default apps): is used to run user workloads
Depending on the requirements of the platform you are planning to build, you may have more than two environments.
Architecture Considerations
When you start designing your platform architecture, one of the first questions is how many environments and how many clusters do I need? Before we can answer this, let's get a clear picture of the relationship between the different parts your platform is composed of:
- A platform has a single code base
- The code base is applied against two or more environments
- The code base defines one or more clusters
- Each cluster has one or more node pools
- Each cluster has zero or more platform services
Kubernetes can provide isolation for tenants and types of workloads with built-in features, or by leveraging its ecosystem. Such capabilities can be used instead of, or in addition to, adding more node pools, clusters and environments.
Environments
Environments control the order changes are applied in. Any change is first reviewed, before it is validated against the internal ops environment. Then it would be promoted to the external apps environment that runs the application workloads for all application environments. So if you want to add another layer of protection and prevent a problematic change from affecting non-prod and prod workloads at the same time, use separate non-prod and prod environments.
Clusters
Clusters provisioned by Kubestack, no matter if they are in the same or in different environments, do not share any infrastructure resources. So issues affecting one cluster, are unlikely to affect other clusters, unless for regional or provider level failure scenarios. But every change is applied to all platform components including clusters in the same environment at the same time.
Cluster names consist of a name prefix, the environment name and the name of the cluster's region. Use the name prefix to reflect the tenant or type of workload a cluster is dedicated to. If you expect that the workloads of a tenant or the workloads of the same type are likely to outgrow the maximum capacity of a single Kubernetes cluster at some point, consider including a count in the name prefix.
Node Pools
Node pools can be used to separate tenants or workload types using taints and tolerations. You will also use different node pools to have nodes with different CPU to memory ratios. Scheduling workloads that require different CPU architectures or GPUs is another common use-case for node pools.
Services
Most services do not affect the platform architecture. But like all platform components, they are per environment. This can be used to have authentication against a common identity provider to access all workloads across all clusters in an environment. Or to provision a cross-cluster service mesh that likewise follows the same environmental boundaries.
Workloads
Do not maintain application workload manifests inside the platform repository. Include everything required so that your platform is ready to run workloads. But exclude manifests that merely define workloads.
Examples commonly included:
- Ingress controllers or service meshes, but not the ingress or mesh resources.
- Operators, and their custom resource definitions. But not their custom resources.
- Admission controllers for policy enforcement and the policies.
- Monitoring and logging exporters/agents/forwarders.
Deploying application workloads as part of the Kubestack automation is discouraged, because it breaks separation between the platform and application layer and often leads to circular dependencies.
Blast-radius Protection vs. Efficient Utilization
Every additional environment, cluster or node pool increases the blast-radius protection but also increases overhead.
- Environments add more protection and overhead than clusters.
- Clusters add more protection and overhead than node pools.
With that in mind:
-
To separate non-production and production workloads:
- use node pools, if you want to prioritize low overhead over blast-radius protection
- use environments, if you want to prioritize blast-radius protection over efficient resource utilization
- do not use clusters, because it would mean more overhead and less blast-radius protection
-
To separate tenants or types of workloads
- use node pools, if you want to prioritize low overhead over blast-radius protection
- use clusters, if you want to prioritize blast-radius protection over efficient resource utilization
- do not use environments, because it would dramatically increase the effort to promote changes
Scaling Platforms
Starting with the minimal starter scaffolded by default, you have various options to scale your platform by adding node-pools, clusters or a third environment. Naturally, you can also remove node-pools, clusters or even entire environments if necessary.
Migrating workloads between clusters, no matter if in the same or different environments, is highly disruptive for the development team and the app's users.
So for a non-prod and prod split, add the environment before opening the platform up to users. And for separating types of workloads or tenants, add the clusters, then onboard the tenant or workload.
To avoid having to migrate applications as the number of apps or their resource usage grows, onboard new apps to new clusters before any cluster reaches the maximum capacity of a single Kubernetes cluster.
Based on the minimal starter (Example 1), you can extend and grow your platform to meet more requirements or increasing adoption in multiple dimensions:
-
Add more node-pools to
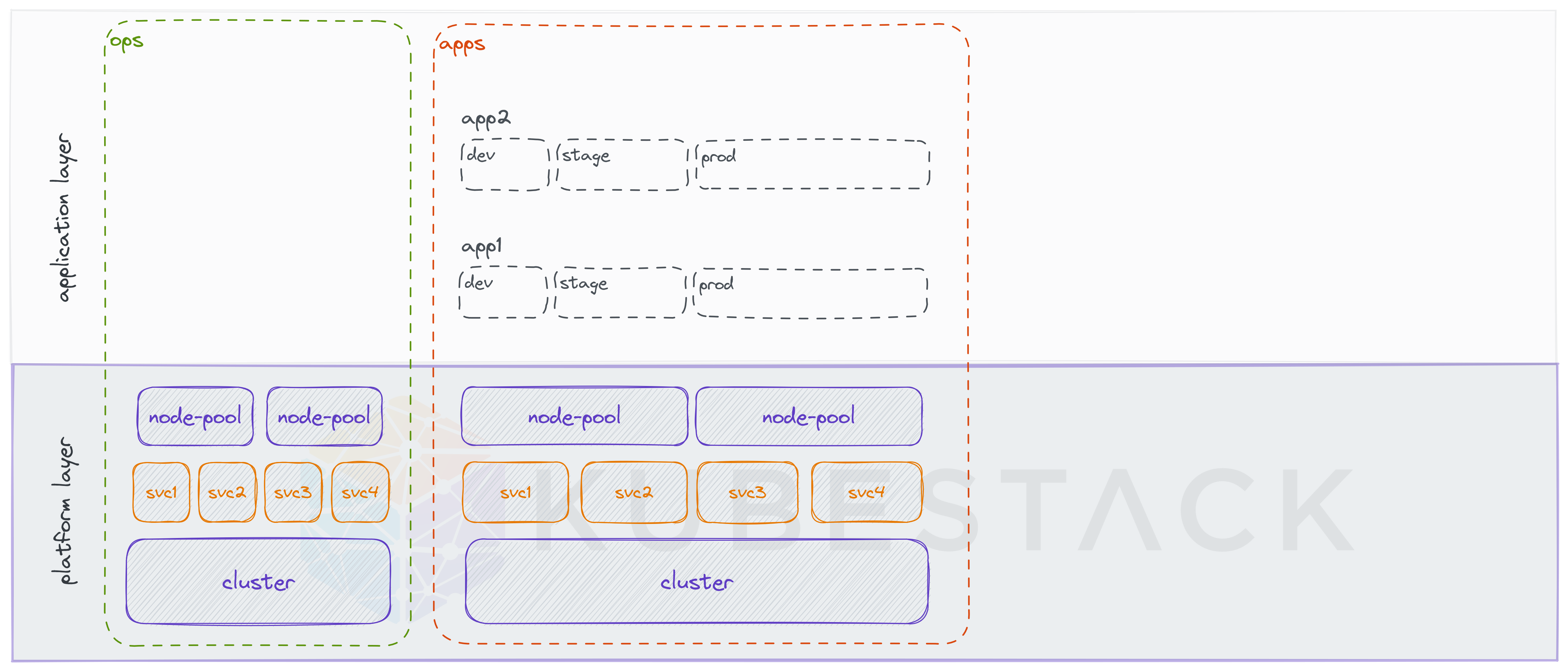
- separate non-prod and prod workloads (Example 2)
- provide hardware capabilities like, different CPU/memory ratios, new CPU architectures or GPUs
- separate types of workloads like web applications from machine learning or API gateways from their backend microservices
-
Adding more clusters to
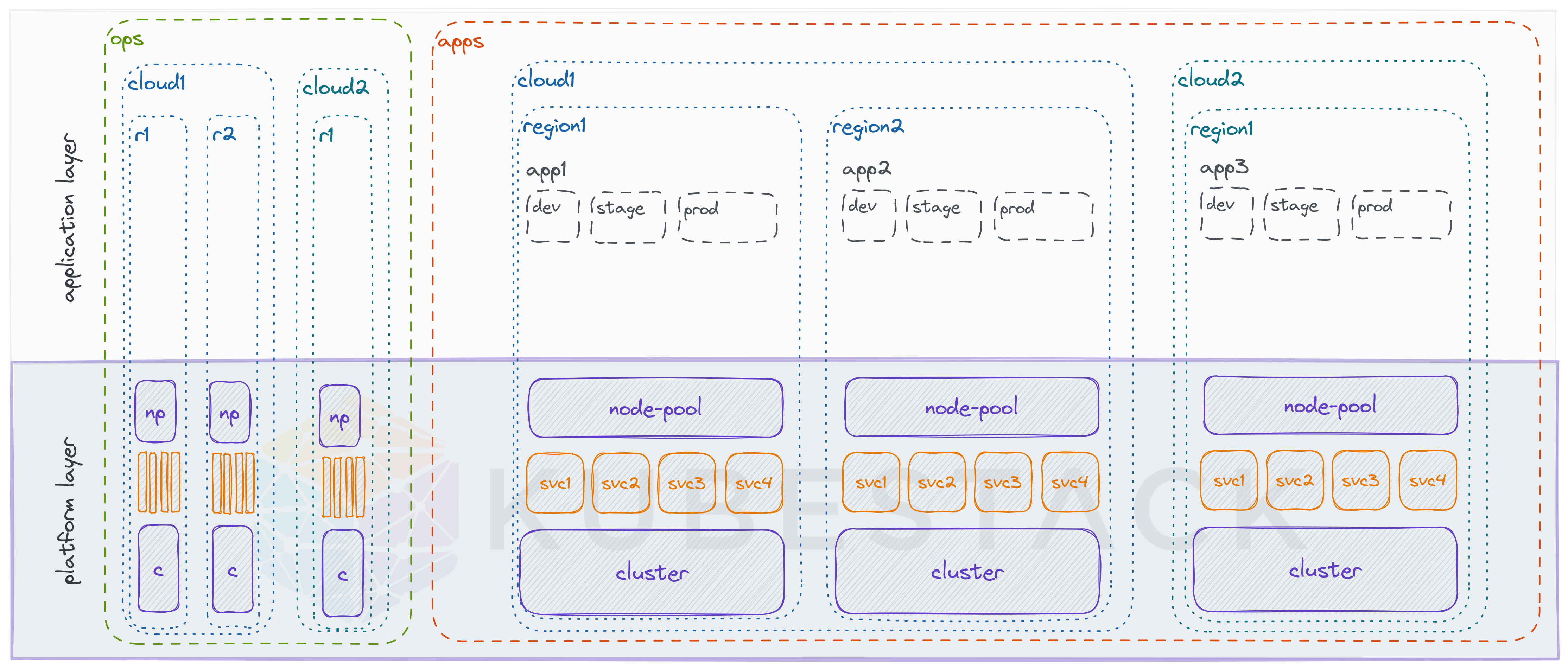
- support multi-region or multi-cloud requirements (Example 3)
- dedicate clusters to types of workloads, e.g.
- web applications
- machine learning
- CI/CD runners
- separate major apps from different organizational units, think Gmail vs. YouTube
-
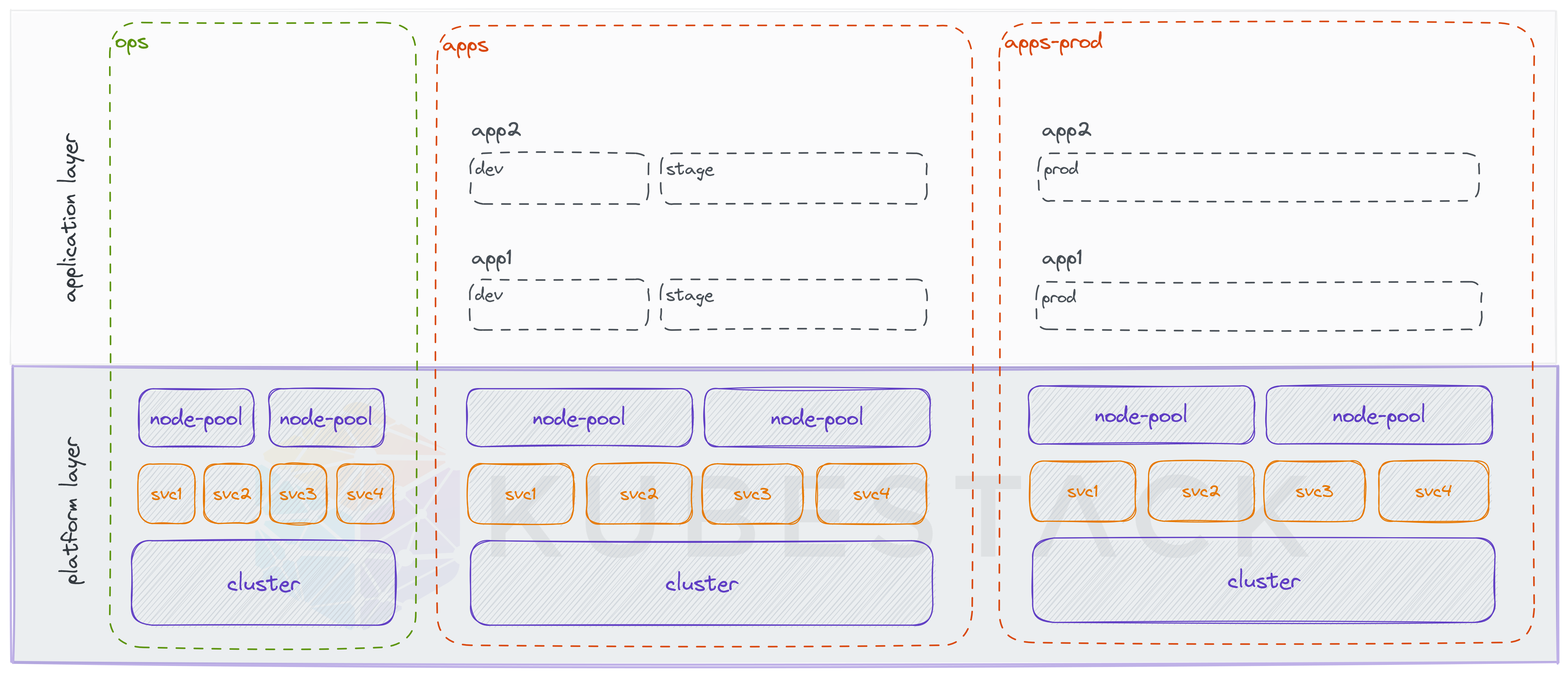
Adding another environment to separate non-prod and prod workloads (Example 4)
Example Architectures
You can combine aspects of the below examples in many ways to meet your platform's requirements.
A Kubestack platform can support all the following at once:
- three environments to split non-prod and prod workloads
- 3 separate clusters per environment, 2 for different tenants (one AWS, one GKE) and 1 just for CI/CD runners (on AKS)
- and finally, different node-pools per cluster to match pod to node CPU/memory ratios efficiently, or to support more CPU architectures and GPUs
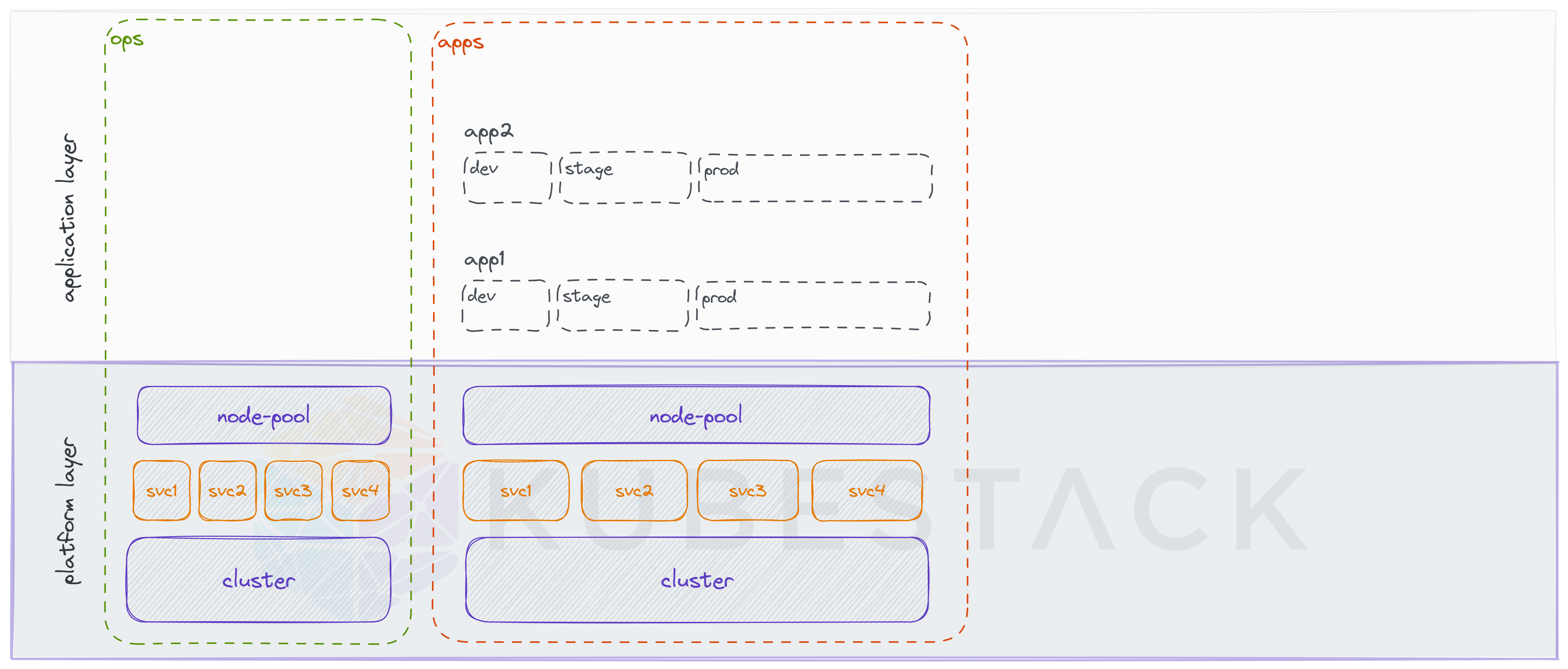
Example 1: Minimal starter
This is the minimal starter the kbst CLI scaffolds by default.
One cluster and two environments.
The internal ops environment, to validate any change before it is promoted.
And the apps environment, that runs all the application environments.
Example 2: Separate non-prod and prod workloads (using node-pools)
Node-pools can be used to separate non-prod and prod workloads by tainting the prod node-pool and requiring prod-workloads to tolerate the taint. But an extra node pool with a taint is also commonly used to keep regular workloads off of GPU instances, for example.
Example 3: Multi-region or multi-cloud
Multiple clusters per environment can be from the same cloud provider, in one or multiple regions. And they can be from different cloud providers.
Example 4: Separate non-prod and prod workloads (using environments)
Three environments can be used to separate non-prod and prod workloads at runtime and only apply changes to non-prod first, before they are also promoted to prod workloads.